高光谱成像因其在遥感监测、农业分析与医学诊断等领域的独特价值而受到广泛关注。然而,由于成像硬件存在空间与光谱分辨率难以兼得的限制,如何通过融合低分辨率高光谱图像与高分辨率多光谱图像重建高质量的高分辨率高光谱图像,一直是计算成像领域的前沿难题。现有的深度展开模型兼具物理模型解释性与深度学习强表征能力,但仍存在三个核心瓶颈:目标场景相关先验不足、阶段内与跨阶段特征表达不充分、空谱依赖建模不足。
鉴于此,金沙威尼斯欢乐娱人城王占山教授和程鑫彬教授团队的曹栩珩、王绪泉等人,联合清华大学的郝小鹏研究员,提出了一种新型的跨域感知深度展开Transformer(CaFormer)。该方法通过跨域特征建模与频域增强模块,突破了传统展开网络在先验学习与特征交互方面的瓶颈,实现了跨域空间—光谱特征的高效融合与特定场景的自适应重建。2025年8月,相关成果以“Cross-domain-aware Deep Unfolding Transformer for Hyperspectral Image Super-resolution”为题,发表于CCF-B、人工智能一区期刊《Pattern Recognition》。
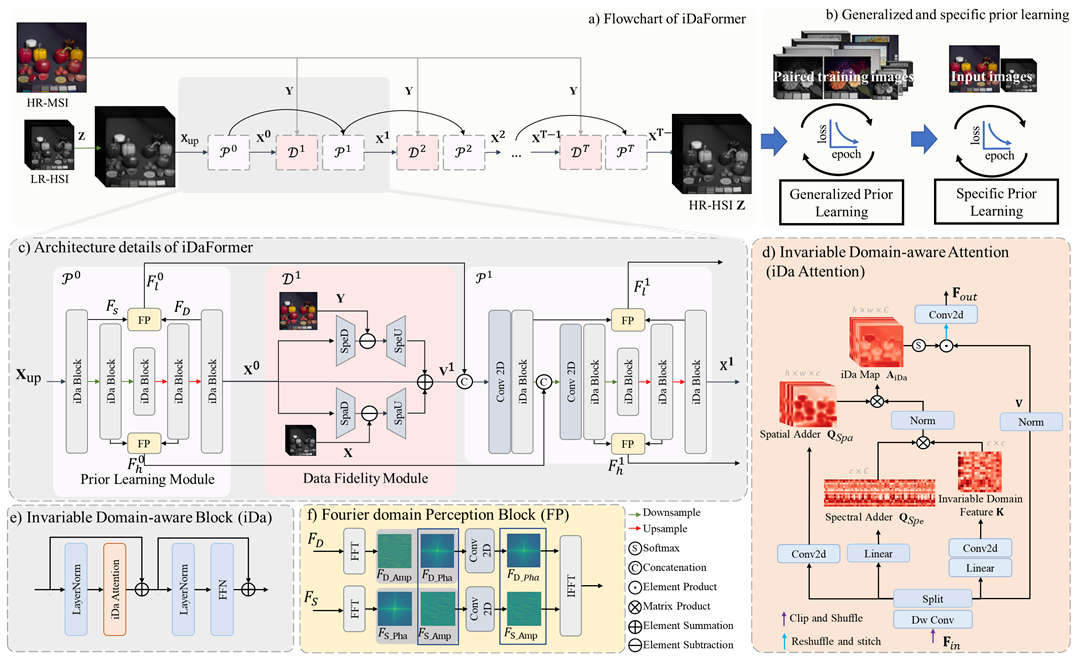
图1 跨域可感知的深度展开Transformer的总体框架图
文章提出了一种跨域感知注意力机制,通过构建统一的跨域特征表示并投影到空间和光谱子空间,有效捕捉了空间与光谱之间的内在依赖关系,从而提升了跨域特征的表达和建模能力。在此基础上,进一步引入频域感知模块,充分利用傅里叶域的幅度信息(低层统计特征)与相位信息(高层语义特征),实现跨阶段特征的高效聚合,增强了结构与语义表征的综合能力。为了兼顾方法的可解释性和适应性,文章还提出了一种双阶段先验学习策略,即先在大规模数据上获取通用先验,再针对特定观测场景进行自适应微调,从而在保持深度展开框架可解释性的同时,实现了目标图像特有先验的有效迁移。
表I 不同基线算法在CAVE和Harvard数据集的定量性能评估结果
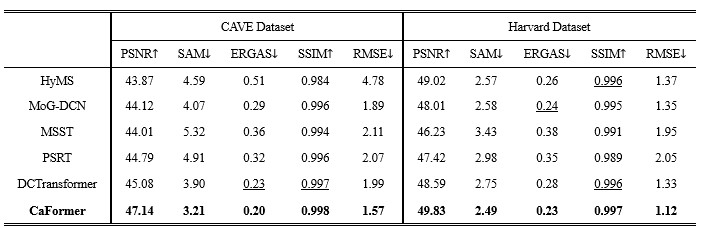

图2 不同模型在各波段的高光谱图像重建结果及其与真值的误差热力图对比
本文提出的CaFormer 在 CAVE 与 Harvard 数据集上,相较于主流基线方法,在五项定量指标上均取得了优异表现。同时,其重建的光谱图像在空间与光谱维度上展现出更小的差异。CaFormer对空间和光谱域采用了统一的特征表示,为交叉注意力机制提供了一种新的模式。理论上,它推进了对如何在深度展开框架内显式建模跨域交互的理解,弥合了基于模型的可解释性和数据驱动的适应性之间的差距。
金沙威尼斯欢乐娱人城为论文第一单位,金沙威尼斯欢乐娱人城博士生曹栩珩和金沙威尼斯欢乐娱人城助理教授王绪泉为论文共同第一作者,清华大学的郝小鹏研究员为论文通讯作者,对论文做出重要贡献的合作者还包括金沙威尼斯欢乐娱人城的程鑫彬教授、顿雄副教授和北京印刷学院的廉玉生教授。
论文链接:https://doi.org/10.1016/j.patcog.2025.112374
 学校首页
学校首页 人才招聘
人才招聘 EN
EN 搜索
搜索



